



Achieving Closed-Loop SRE Benefits
- September 08, 2021
‘Treat operations like development’ is the mantra of Site Reliability Engineering (SRE). It’s also now a key mantra for the Operations team at our telecommunications client. Responsible for managing the availability and reliability of one of the company’s leading client-facing enterprise applications, the Operations team turned to NTT DATA to help it implement SRE and gain visibility and faster feedback from the product allowing it to proactively respond to emerging instabilities in the product.
While the Operations team has access to engineers to help repair issues associated with the application they manage, this approach raised two concerns. First, the process was often lengthy, having to raise a ticket, wait for resources and then wait for the actual repair. Second, Operations lacked insight into what was done to fix the issue, making it more difficult to effectively navigate future issues.
Wanting greater visibility, a more rapid response and faster time to resolution, the client adopted a novel, yet common-sense approach to issue resolution using SRE and NTT DATA expert guidance. The model is comprised of several steps, including:
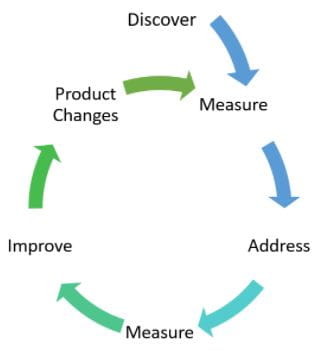
- Discover – The first step of the process is to find the root of the problem, collect all possible information about it and determine the best way(s) to measure it. For example, the way to measure slow app response times may be much different than issues around a rules engine. This step also includes assessing any current metrics to ensure that they are the right ones for the problem and add any missing measurements.
- Measure – With measures defined, the next step in the SRE problem resolution process is to deploy the metrics, creating a baseline for future measurement. This process may also reveal additional problem areas.
- Address – With a firm understanding of the problem and how it’s impacting key measures, the Operations team’s next task is to repair the issue within the problem area.
- Measure – With the fix in place, the team measures once again to determine the impact the repair has had on the application. Measuring progress in this way allows the team to get immediate feedback on the quality of the repair – and to determine if the problem needs to be addressed by multiple fixes. Moreover, by taking a new baseline snapshot after each iteration, (vs. making several repairs and guessing which repair fixed the issue) the team can track iterative improvements and/or immediately roll-back efforts that did not improve the issue.
- Improve – With repairs made, the Operations team is now able to begin implementing continuous improvements, for example, updating code or infrastructure systems that will provide greater efficiency for the team and enhance reliability for customers.
- Product Changes – Last, the team can make changes to the product itself, adding functionality, or otherwise improving its operation.
Putting SRE into action
Previously when our client had an app-related issue, the team would begin a manual process whereby they would talk to customer service, support, sales and/or other groups to gather as much data as they could about the nature of the problem. What they collected tended to be anecdotal in nature and focused on symptoms of the problem, rather than the root cause. To begin collecting verifiable, repeatable system metrics the team turned to Datadog.
With the help of NTT DATA cloud consultants, the Operations team implemented as code Datadog dashboards, monitors and alerts for each of its app subsystems. This allows it to now define and gauge metrics like system capacity levels, usage stats, deployed versions, error rates and so on. With initial thresholds in place, they can now monitor and alert around these levels. They can fine-tune thresholds, which is especially helpful as the team continues to improve and optimize its systems. Moreover, they also have better visibility over the entire fleet of servers which is particularly helpful to be able to respond early and quickly against many different problems.
Making repairs
As part of the SRE process, the Operations team identified and prioritized several issues. Tackling each one using the process defined above, they found that some issues were immediately improved with the repair of just a single defect. While unexpected, these cases proved the value of measuring with each iteration as doing so allowed the team to move on to the next issue much more quickly, saving it countless hours.
This is in line with the true nature of Scrum which NTT DATA’s Agile teams follow in their delivery model. This approach allows the NTT DATA team to maximize value for clients, which they did in this case by applying Scrum's emphasis on addressing high value features first to prioritize and focus on issues that could create the most value once fixed.
Other issues required the team to make a repair, measure and continue making repairs until the metric reached a quality threshold. This constant evaluation netted fast success, drastically reducing mean time to repair and error rates. For example, the team was able to repair an issue that once registered 1,000 errors per week to just 12.
Product improvements
With repairs made, the team’s next step was to pursue product improvements, which were made with the help of the NTT DATA team who refactored the client’s application code to take advantage of cloud-native functionality. Working in the application’s core modules -- and most critical, yet complex modules of the product -- the NTT DATA team delivered on the client’s mandate that all product refactoring done to optimize, improve or fix a defect was implemented with complete transparency to the end user. This sped time-to-repair by removing project management, release management and other teams from the process. Notably, each change is delivered using a feature flag that allows the team to quickly revert to a working or acceptable model should the need arise.
The NTT DATA cloud specialists also improved issues like scheduled jobs that were experiencing issues. They did so by capturing how many scans are running at the same time and/or how many are timing out and then implementing random logic to running scans to avoid system resource contentions.
Product changes
NTT DATA engineers also made product changes, such as updating the application API with new features that show rules status. For example, if a rule uses excess system resources, the product improvement would now show the end user that the rule is running slowly due to system demand. The new rule status increases issue visibility, making it even easier for Operations to troubleshoot.
The team also fixed issues with customers exceeding their resource limits which caused additional downstream complications within the product. The NTT DATA team implemented limits in data processing as a new product feature, causing customers that crossed their data limit to be notified with new data processing automatically stopped by the product. These efforts resulted in a more robust application, with faster load times, less resource usage and more.
All told, the teams working together were able to identify areas for product improvement that are expected to boost the application’s performance by an estimated 20%-30%.
Measuring correctly
Last, the NTT DATA team helped create metrics to measure problem areas. For example, metrics related to the orchestration of rules, source and application disconnects, and exceeding limits set by business, were all created. These metrics allow the client to accurately gauge whether a particular issue should be closed or if it requires further work. In addition, the cloud transformation team:
- Fine-tuned, enabled and optimized log generation and collection to increase end user visibility into potential problems that may hamper system performance.
- Calibrated the client’s logs and log levels; by sanitizing logs and helping define limits and alerts, the NTT DATA team was able to help the client’s engineers more easily trace errors, saving them significant time.
Benefits of SRE visibility
In addition to its newly defined metrics letting the team know where they are successful, they also alert them to where they need to spend more time. And the Operations team is now able to proactively detect issues before customers do, giving them critical time to fix errors before they impact users. With Datadog metrics, the telecom team can also now unearth areas where product changes can be made to make the application even more efficient for customers. With NTT DATA’s help, the team has made several such changes that have resulted in smarter wizards, faster processing times and more. As a result, customer satisfaction with the application has grown and users are making even more effective use of the solution.
Subscribe to our blog